
Google, metni kelime kelime üretmek yerine difüzyon yöntemiyle oluşturan, açık ağırlıklara sahip deneysel bir model yayımladı. Tek bir GPU üzerinde, tek kullanıcılı modda klasik dil modellerine kıyasla dört kata kadar daha hızlı çalışıyor. Optimizasyon sürecini ise Nvidia üstlendi.
Çoğu dil modeli, her yeni tokenı bir öncekine dayandırarak art arda üretir. DiffusionGemma ise farklı bir yaklaşım benimsiyor. İşleme 256 rastgele yer tutucu token içeren bir blokla başlıyor ve okunabilir bir metin ortaya çıkana kadar bunları birkaç adımda netleştiriyor. Fikir, difüzyon modellerinin gürültüyü net görüntülere dönüştürdüğü görsel YZ alanından geliyor.
Model toplamda 26 milyar parametre barındırıyor ancak adım başına yalnızca 3,8 milyarını aktif hale getiriyor. Bu durum, birkaç uzmanlaşmış alt ağın yan yana durduğu ve girdiye göre yalnızca doğru ağların tetiklendiği uzmanların karışımı (mixture-of-experts) mimarisi sayesinde gerçekleşiyor. Google, model daha düşük hassasiyete indirgendiğinde (kuantize edildiğinde) üst segment tüketici GPU’larındaki 18 GB VRAM alanına sığdığını belirtiyor. Model, Gemma 4 ailesi üzerine inşa edilmiş ve difüzyon sürecini Google’ın Gemini Diffusion hakkındaki önceki çalışmalarından alıyor.
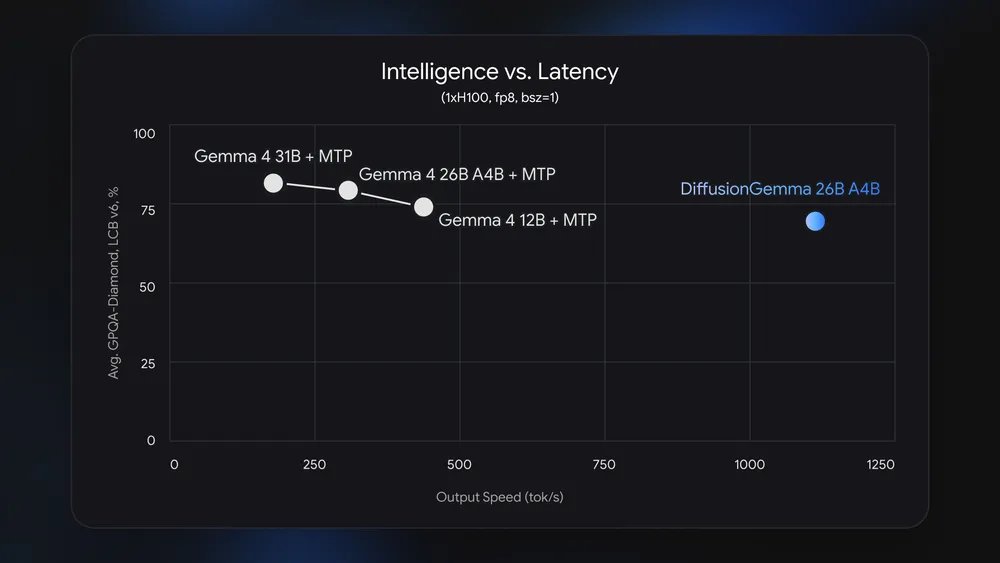
Hızın Kaynağı GPU Verimliliği
Nvidia, hız avantajının tamamen donanım kullanımıyla bağlantılı olduğunu belirtiyor. Autoregressive modellerde, tek kullanıcılı çıkarım (inference) genellikle bellek bant genişliği nedeniyle darboğaza takılıyor. GPU’nun hesaplama birimleri zamanın çoğunda boşta kalıyor ve sadece bellekten veri bekliyor. Mühendisler bu durumu memory-bound olarak adlandırıyor. DiffusionGemma, 256’ya kadar tokenı paralel işleyerek bu sorunun etrafından dolaşıyor ve darboğazı ham hesaplama gücüne doğru itiyor. Sonuç olarak GPU’lar sürekli aktif kalıyor.
Nvidia, tek bir isteği işlerken H100 üzerinde saniyede yaklaşık 1.000 token, DGX Spark masaüstü sisteminde saniyede 150 token ve DGX Station üzerinde saniyede 2.000 token’a kadar ulaşıldığını aktarıyor. Google, GeForce RTX 5090 ekran kartında saniyede 700 tokendan fazlasının üretildiğini belirtiyor. Yerel tek kullanıcılı modda model, özel GPU’larda benzer bir özbağlanımlı modele kıyasla yaklaşık dört kat daha hızlı çalışıyor.

Google bu performansı özel hızlandırıcılara bağlıyor. Çıkarım sırasında bellek bant genişliği sınırına takılan Apple Silicon gibi paylaşımlı bellek mimarilerinde, özbağlanımlı modellerle olan farkın daha küçük kalacağı öngörülüyor.
Çok sayıda paralel isteğin yer aldığı bulut servislerinde ise durum tersine dönüyor. Google, özbağlanımlı modellerin bu senaryoda donanımı zaten tam kapasite çalıştırdığını, bu yüzden DiffusionGemma’nın maliyetleri aslında yukarı çekebileceğini belirtiyor.
Hız Kalite Maliyetiyle Geliyor ama Yeni Kullanım Alanları Açıyor
DiffusionGemma, yüksek hız elde etmek adına çıktı kalitesinden ödün veriyor. Google, kalitenin kritik önem taşıdığı durumlar için normal Gemma 4 modellerini önermeye devam ediyor. DiffusionGemma’yı ise yerel ve hızlı iş akışları üzerinde çalışan araştırmacılar ile geliştiricilere yönelik bir araç olarak konumlandırıyor.
Google’ın asıl güçlü gördüğü alanlar, soldan sağa işlemeyen görevler. Model tüm bloğu aynı anda değerlendirdiği için, üretim sırasında her token diğer tüm token’lara, hatta daha sonra gelecek olanlara bile referans verebiliyor. Geleneksel dil modelleri ise yalnızca geriye bakabiliyor.
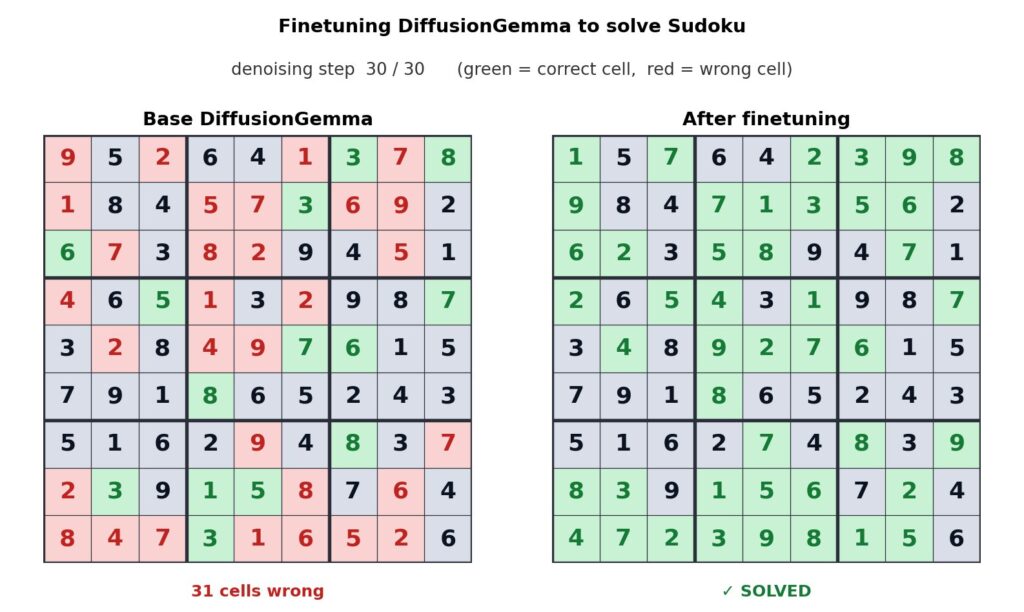
Söz konusu yetenek, mevcut paragraflara metin ekleme, kod bloklarındaki boşlukları doldurma veya amino asit dizilimleri ile matematiksel grafikler gibi yapılandırılmış verilerle çalışma süreçlerini kolaylaştırıyor. Google, DiffusionGemma’nın Sudoku çözdüğü bir Unsloth ince ayarını (fine-tune) buna örnek gösteriyor. Autoregressive modeller bu görevde zorlanıyor çünkü her giriş, daha sonraki girişlere bağlı oluyor.
İlk Günden İtibaren Geniş Araç Desteğiyle Açık Ağırlıklar
Model ağırlıkları Apache 2.0 lisansı altında Hugging Face platformunda yer alıyor. DiffusionGemma; Hugging Face Transformers, vLLM (Red Hat entegrasyon desteğiyle) ve MLX gibi popüler çıkarım kütüphaneleriyle doğrudan uyumlu çalışıyor. İnce ayar işlemleri için Google; Unsloth ve Nvidia NeMo Framework yazılımlarının yanı sıra kendi JAX araç kiti Hackable Diffusion sistemine işaret ediyor. llama.cpp desteği ise planlanıyor.
Nvidia, modeli RTX 5090 ve 4090 için kuantize ederek yerel masaüstü kurulumlarına yönelik DGX Spark ile DGX Station da dahil olmak üzere Hopper ve Blackwell sunucu mimarilerine uyarladı. Model ayrıca Gemini Enterprise Agent Platform Model Garden ve Nvidia NIM üzerinden de erişime açıldı.
Google ek olarak bir DiffusionGemma geliştirici kılavuzu yayımladı. Maarten Grootendorst da sistemin işleyişini açıklayan görsel bir rehber hazırladı.
Gemini Diffusion Temeli Attı
Google Deepmind, Gemini Diffusion projesiyle metin tabanlı bir difüzyon modelinin erken aşamadaki deneysel gösterimini daha önce yapmıştı. O dönemde Deepmind saniyede 1.479 token gibi yüksek hızlara ulaşıldığını belirtiyordu. Performans testlerinde Gemini Diffusion, kabaca Gemini 2.0 Flash-Lite ile kafa kafaya sonuçlar veriyor.
Girişim şirketi Inception da aynı paralel difüzyon yaklaşımını takip ediyor. Şirketin, ilk difüzyon tabanlı muhakeme modeli olarak tanımladığı Mercury 2, 2026 yılının başlarında kullanıma sunuldu.
Kaynak: https://the-decoder.com/googles-new-open-model-diffusiongemma-generates-text-from-noise-instead-of-word-by-word/



