Üretken YZ modellerinin iç işleyişi hakkında çok şey bilmeseniz bile, çok fazla belleğe ihtiyaç duyduklarını muhtemelen biliyorsunuzdur. Bu nedenle, bugünlerde fahiş fiyatlar ödemeden küçük bir RAM modülü satın almak neredeyse imkansız. Google Research, kısa süre önce LLM‘lerin bellek ayak izini azaltırken hızı artıran ve doğruluğu koruyan bir sıkıştırma algoritması olan TurboQuant’ı tanıttı.
TurboQuant, Google’ın önemli bilgileri saklayarak yeniden hesaplanmalarını önleyen bir “dijital kopya kağıdı” olarak nitelendirdiği anahtar-değer önbelleğinin (key-value cache) boyutunu küçültmeyi hedefliyor. Bu kopya kağıdı oldukça gerekli çünkü LLM‘ler aslında hiçbir şey bilmiyor. Sadece, tokenize edilmiş metnin anlamsal karşılığını haritalayan vektörler aracılığıyla bilgi sahibiymiş gibi bir izlenim yaratıyorlar. İki vektör birbirine benzediğinde, bu durum kavramsal bir benzerlik olduğu anlamına geliyor.
Yüzlerce veya binlerce parametre içerebilen yüksek boyutlu vektörler, bir görüntüdeki pikseller veya büyük bir veri seti gibi karmaşık bilgileri tanımlayabiliyor ancak bu vektörler çok fazla bellek kaplıyor ve önbellek boyutunu şişirerek performansı düşürüyor.
Geliştiriciler, modelleri daha küçük ve verimli hale getirmek için onları daha düşük hassasiyette çalıştıran “quantization” (nicemleme) tekniklerini kullanıyor ama bu durum çıktı kalitesinin düşmesine ve kelime tahmin kalitesinin azalmasına yol açıyor. TurboQuant ile Google’ın ilk sonuçları, bazı testlerde kalite kaybı yaşanmadan 8 kat performans artışı ve 6 kat bellek tasarrufu sağlandığını gösteriyor.
Açılar ve Hatalar
TurboQuant’ı bir modele uygulamak iki aşamalı bir süreçten oluşuyor. Yüksek kaliteli sıkıştırma elde etmek için Google, PolarQuant adında bir sistem geliştirdi. Normalde modellerdeki vektörler standart XYZ koordinatları kullanılarak kodlanıyor fakat PolarQuant bunları Kartezyen sistemindeki kutupsal koordinatlara dönüştürüyor. Bu dairesel ızgara üzerinde vektörler iki bilgiye indirgeniyor: bir yarıçap (verinin gücü) ve bir açı (verinin anlam yönü).
Google bu süreci açıklamak için ilginç bir günlük hayat analojisi sunuyor. Vektör koordinatları yol tarifi gibidir; geleneksel kodlama “3 blok doğuya, 4 blok kuzeye git” şeklinde olabilir ama Kartezyen koordinatlar kullanıldığında bu sadece “37 derece açıyla 5 blok git” anlamına geliyor. Bu yöntem daha az yer kaplıyor ve sistemi maliyetli veri normalleştirme adımlarından kurtarıyor.
Sıkıştırmanın büyük kısmını PolarQuant yapıyor ancak ikinci adım hataları temizliyor. PolarQuant etkili olsa da geride bazı kalıntı hatalar bırakabiliyor. Google, bu pürüzleri “Quantized Johnson-Lindenstrauss (QJL)” adı verilen bir teknikle gidermeyi öneriyor. Bu yöntem, modele 1 bitlik bir hata düzeltme katmanı ekleyerek her vektörü (+1 veya -1) tek bit ile temsil ediyor ve vektörler arasındaki temel ilişkileri koruyor. Sonuç olarak, sinir ağlarının hangi verinin önemli olduğuna karar verdiği temel süreç olan dikkat puanı (attention score) daha doğru hesaplanıyor. Daha fazla detay merak ediyorsanız, ön baskı makalesi indirilebilir durumda.
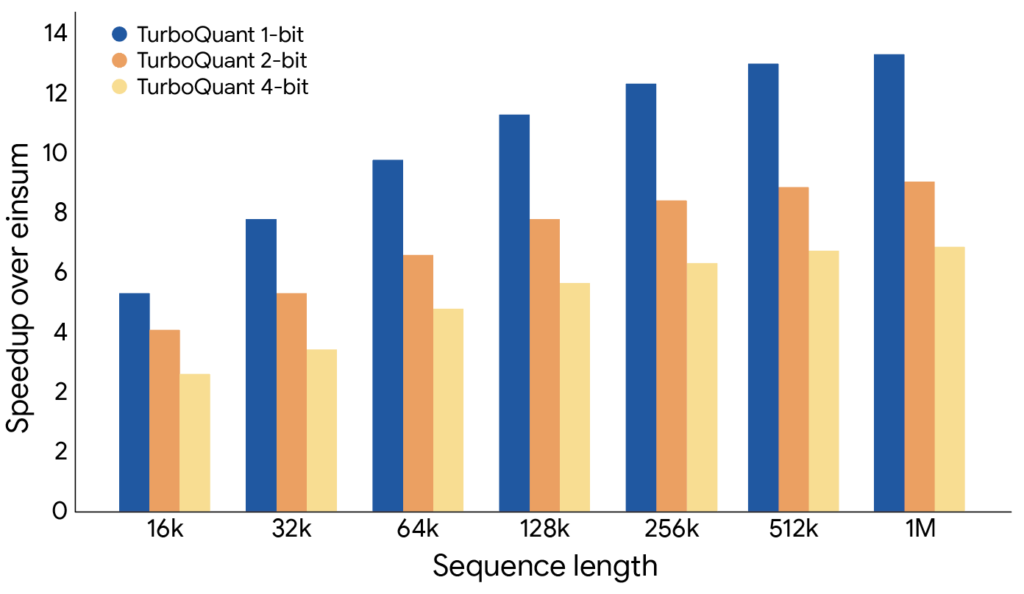
Peki tüm bu matematiksel hesaplamalar işe yarıyor mu? Google, yeni algoritmik sıkıştırmayı hem Gemma hem de Mistral açık modellerini kullanarak bir dizi uzun bağlamlı testte denediğini belirtiyor. TurboQuant, önbellekteki bellek kullanımını 6 kat azaltırken tüm testlerde mükemmel sonuçlar verdi. Algoritma, ek bir eğitime gerek duymadan önbelleği sadece 3 bite kadar sıkıştırabiliyor; böylelikle mevcut modellere uygulanabiliyor. 4 bitlik TurboQuant ile dikkat puanını hesaplamak, Nvidia H100 hızlandırıcılarında 32 bitlik sıkıştırılmamış verilere kıyasla 8 kat daha hızlı gerçekleşiyor.
TurboQuant hayata geçirilirse, YZ modellerinin çalıştırılması daha ucuz ve daha az bellek tüketen bir hale gelebilir. Bununla birlikte, bu teknolojiyi yaratan şirketler serbest kalan belleği daha karmaşık modeller çalıştırmak için de kullanabilir. Muhtemelen her ikisinin bir karışımı olacak ancak en büyük faydayı mobil YZ görecek. Akıllı telefonların donanım kısıtlamaları göz önüne alındığında, TurboQuant gibi sıkıştırma teknikleri, verileri buluta göndermeye gerek kalmadan çıktı kalitesini artırabilir.
Kaynak: https://arstechnica.com/ai/2026/03/google-says-new-turboquant-compression-can-lower-ai-memory-usage-without-sacrificing-quality/



