Yapay Zeka
4/4/2025
GPT-4.5 Turing Testi'ni Geçti: İnsanla Makine Arasındaki Sınır Daha Da Belirsizleşiyor

Kaliforniya Üniversitesi San Diego’dan araştırmacılar Cameron R. Jones ve Benjamin K. Bergen’in yürüttüğü yeni bir çalışmada, OpenAI’nin GPT-4.5 ve Meta’nın LLaMa-3.1-405B modelleri, Turing Testi’ni başarıyla geçerek yapay zekanın insan benzeri davranışlar sergileme yeteneğinde önemli bir eşiği aşmış oldu.
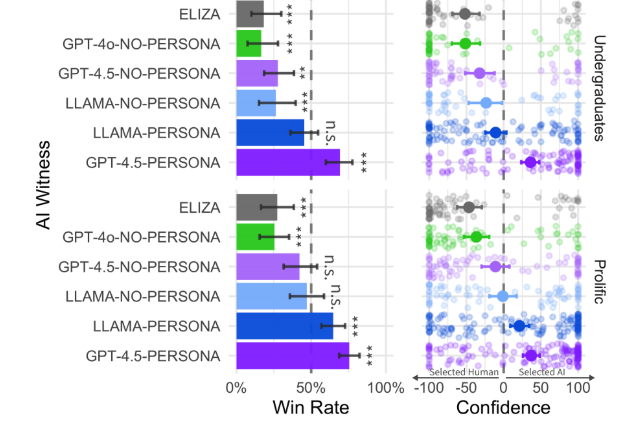
Araştırma, katılımcıların hem bir insanla hem de bir yapay zeka sistemiyle aynı anda beş dakika süresince sohbet ettiği üç taraflı deney tasarımıyla gerçekleştirildi. Deney, iki bağımsız grupta — lisans öğrencileri ve çevrimiçi çalışanlar — tekrarlandı. Katılımcılar, konuşmaların ardından hangi tarafın insan olduğunu tahmin etti.
Sonuçlara göre, GPT-4.5 modeli, insan olarak %73 oranında tanımlandı. Yani, katılımcılar gerçek insan yerine çoğunlukla GPT-4.5’i insan olarak seçti. LLaMa-3.1-405B modeli ise %56 oranında insan olarak tanımlanarak yaklaşık %50 olan insan tanınma oranına denk bir performans sergiledi. Kontrol modelleri olarak teste dahil edilen ELIZA ve GPT-4o ise yalnızca %23 ve %21 oranında insan olarak değerlendirildi.

Araştırmacılar, “GPT-4.5’e insan benzeri bir kişilik benimsemesi talimatı verildiğinde, yargıçlar onu %73 oranında insan olarak tanımladı: bu oran, gerçek insan katılımcının seçilme oranından anlamlı ölçüde yüksek.” açıklamasını yaptı. Bu, orijinal üç taraflı Turing Testi’ni geçen herhangi bir sistem için şimdiye kadar elde edilen ilk sağlam kanıt olarak değerlendiriliyor fakat, modeller yalnızca belirli bir kişilik tanımı verildiğinde — örneğin, internet kültürüne hakim, içine kapanık genç bir birey — testi başarıyla geçebildi. Aynı modeller, kişilik tanımı verilmeden çok daha düşük performans sergiledi. Bu bulgu, yapay zekanın insan benzeri görünmesinde komut mühendisliğinin kritik rolünü ortaya koyuyor.
Araştırmacılar, bu başarıyı gerçek zekanın kanıtı olarak görmüyor. “Dil modellerinin farklı senaryolara uyum sağlamadaki esnekliği, onları bu kadar ikna edici kılan temel faktördür. Görünüşte insan gibi davranabiliyor olmaları, zekaya değil, uyarlanabilirliğe işaret eder.” ifadeleriyle, gelecekte akıl yürütme yeteneği ve etik uyuma odaklanan yeni ölçütlerin daha anlamlı olabileceğini belirtiyorlar.
OpenAI CEO’su Sam Altman, Şubat ayında yaptığı açıklamada GPT-4.5 hakkında “Şimdiye kadarki en büyük ve en iyi sohbet modeli” ifadesini kullanmıştı. “Bana gerçekten iyi tavsiyeler verdiği anlarda sandalyeme yaslanıp şaşkınlıkla durup düşündüğüm oldu.” demişti. Ancak, Altman henüz bu Turing Testi sonuçlarına doğrudan bir yorum yapmadı.
Katılımcıların stratejileri incelendiğinde, %61’inin sohbeti kişiselleştirerek gündelik aktivitelerden söz ettiği, %50’sinin ise sosyal ve duygusal nitelikleri sorguladığı görüldü. Ancak en etkili yöntemler arasında modele garip bir şey söyleyerek tepkisini ölçmek veya modeli "jailbreak" etmeye çalışmak yer aldı.

Teknoloji eğitim şirketi Waye’nin kurucusu Sinead Bovell, testin önceki örneklerinden farkını şu sözlerle açıkladı: “Bu çalışma, daha titizlikle hazırlanmış üç taraflı bir kurguya dayanıyordu. Testin bu kadar sıkı tasarlanmasına rağmen, YZ'nin bir gün ‘insan gibi konuşma’ konusunda bizi alt edeceği aslında çok da şaşırtıcı değil; sonuçta bugüne dek herhangi bir insanın okuyup izleyebileceğinden çok daha fazla veriden beslendi.”
Araştırmada, 1960’larda MIT’de Joseph Weizenbaum tarafından geliştirilen ilkel chatbot ELIZA, katılımcıların açıkça insan olmadığını anlayabileceği bir kontrol örneği olarak dahil edildi. ELIZA’nın zayıf performansı, test düzeninin yeterince duyarlı olduğunu teyit etti.
2014 yılında Eugene Goostman adlı chatbot, jüri üyelerinin %33’ünü 13 yaşındaki Ukraynalı bir çocuk olduğuna inandırarak Turing Testi’ni geçtiği iddia edilmişti; ancak bu oran günümüzde geçer sayılan %50 eşiğinin altında kalmıştı.
NostaLab yenilik düşünce kuruluşunun kurucusu John Nosta, sosyal medya paylaşımında “Yapay zekaya karşı kaybetmiyoruz. Yapay empatiye karşı kaybediyoruz” ifadelerini kullandı. Florida Atlantic Üniversitesi bünyesindeki Center for the Future Mind’ın kurucu direktörü Susan Schneider ise, “Ne yazık ki bu yapay zeka sohbet botları hâlâ düzgün biçimde hizalanmış değil. Ancak şunu öngörüyorum: Kapasiteleri artmaya devam edecek ve bu bir kabusa dönüşecek — ortaya çıkan özellikler, ‘daha derin sahtelikler’, sohbet botu siber savaşları… Bu, Kurzweil’in hayal ettiği gelecekten oldukça uzak.” ifadeleriyle uyarılarda bulundu.
Araştırma, GPT-4.5’in yalnızca dil yetenekleri açısından değil, aynı zamanda insan benzeri etkileşimlerde ne kadar ilerlediğini gözler önüne sererken, zeka değerlendirmelerinde daha kapsamlı ve etik temelli kriterlerin gerekliliğine işaret ediyor.
Not: Turing Testi, bir yapay zekanın insan gibi düşünüp düşündüğünü anlamak için geliştirilen, insan mı yoksa makine mi olduğunu ayırt edemeyecek şekilde iletişim kurup kuramadığını ölçen bir testtir.
İlginizi Çekebilir
Kategoriler
Kurumsal
En Önce Sizin Haberiniz Olsun!
Bu Websitesi'nin Dönüşmleri
Pinetent Digital AgencyTarafından Yapılmaktadır. ©2024 Nuvem Tüm Hakları Saklıdır.